AI Trust in Veterinary Chat Services KI-Vertrauen in veterinärmedizinischen Chatdiensten
How do agent identity and source citations affect user trust, credibility, and willingness to follow advice? Wie beeinflussen Agentenidentität und Quellenangaben Vertrauen, Glaubwürdigkeit und die Bereitschaft, Ratschlägen zu folgen?
Same advice. Different label. +4.4% perceived expertise. Gleicher Rat. Anderes Label. +4,4% wahrgenommene Expertise.
Changing the chatbot's name from "Zähnchen Bot, AI Dental Assistant" to "Lena Bauer, Veterinary Assistant" increased credibility scores — without changing a single word of the actual advice. Die Umbenennung des Chatbots von „Zähnchen Bot, KI Dentalassistent" zu „Lena Bauer, Tiermedizinische Assistentin" erhöhte die Glaubwürdigkeitswerte — ohne ein einziges Wort des eigentlichen Ratschlags zu ändern.
Try the Experiment Probiere das Experiment
I built the chat interface that 414 pet owners interacted with. Same conversation, two different identities. See the difference yourself. Ich habe die Chat-Oberfläche gebaut, mit der 414 Tierbesitzer interagierten. Gleiches Gespräch, zwei verschiedene Identitäten. Sieh den Unterschied selbst.
Three Visualizations That Tell the Story Drei Visualisierungen, die die Geschichte erzählen

Pet owners don't trust AI chatbots for health advice. I wanted to know: what actually builds that trust?
Tierbesitzer vertrauen KI-Chatbots nicht bei Gesundheitsratschlägen. Ich wollte wissen: Was baut dieses Vertrauen wirklich auf?
I tested two specific design choices:
Ich testete zwei spezifische Designentscheidungen:
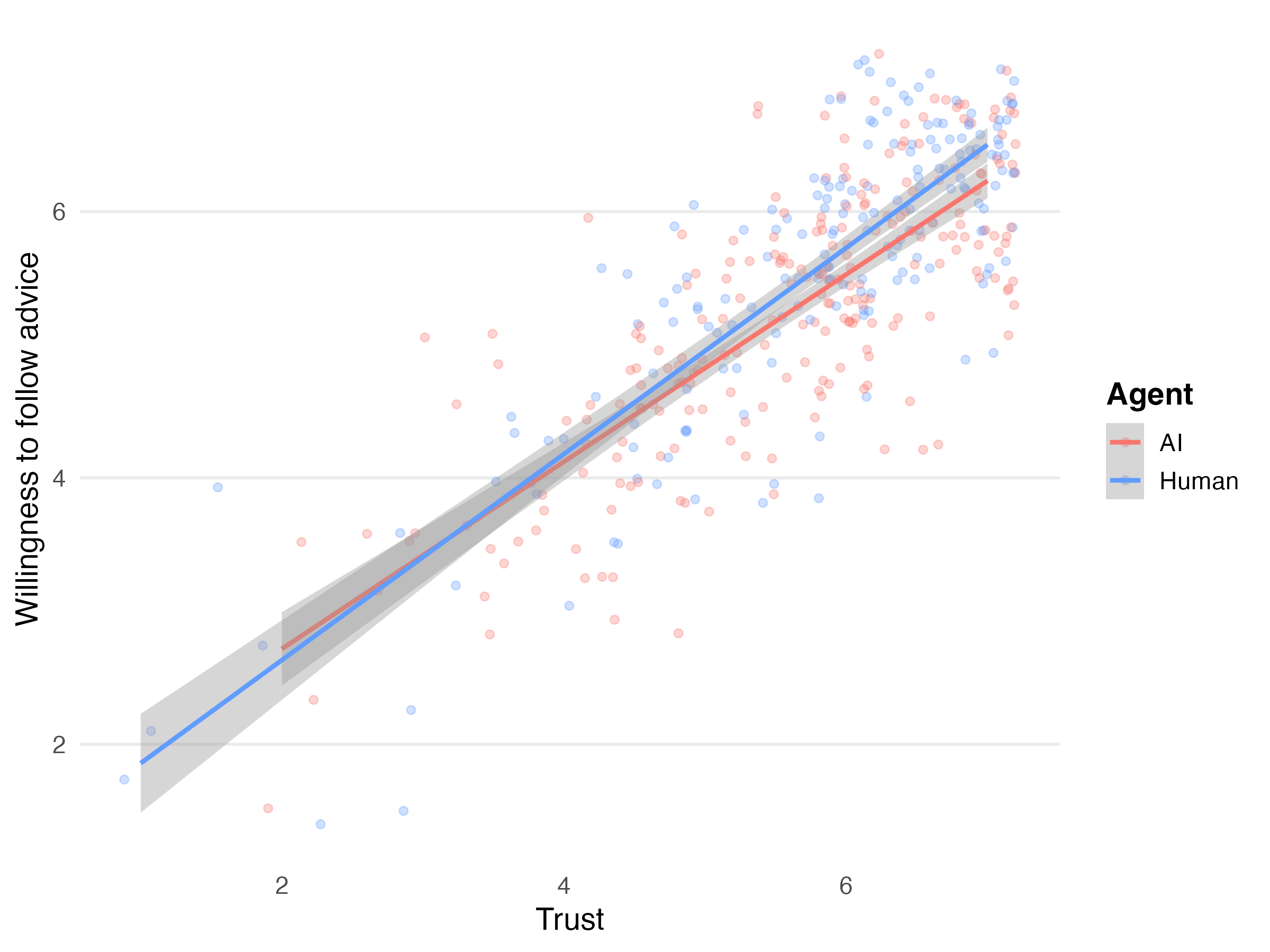
Agent Identity — Does it matter if users think they're talking to "AI" or "a human assistant"?
Agentenidentität — Macht es einen Unterschied, ob Nutzer glauben, mit „KI" oder „einer menschlichen Assistentin" zu sprechen?
Source Citations — Does showing where the advice comes from (AVMA guidelines, veterinary journals) help build credibility?
Quellenangaben — Hilft es der Glaubwürdigkeit, wenn gezeigt wird, woher der Rat stammt (AVMA-Richtlinien, veterinärmedizinische Zeitschriften)?
I ran a preregistered experiment with 414 pet owners from the UK, Germany, Austria, and Switzerland. Each person interacted with a simulated veterinary chat service preparing them for their dog's dental cleaning, then reported how credible, trustworthy, and actionable they found the advice.
Ich führte ein präregistriertes Experiment mit 414 Tierbesitzern aus Großbritannien, Deutschland, Österreich und der Schweiz durch. Jede Person interagierte mit einem simulierten Veterinär-Chatdienst zur Vorbereitung auf die Zahnreinigung ihres Hundes und berichtete dann, wie glaubwürdig, vertrauenswürdig und umsetzbar sie den Rat fanden.
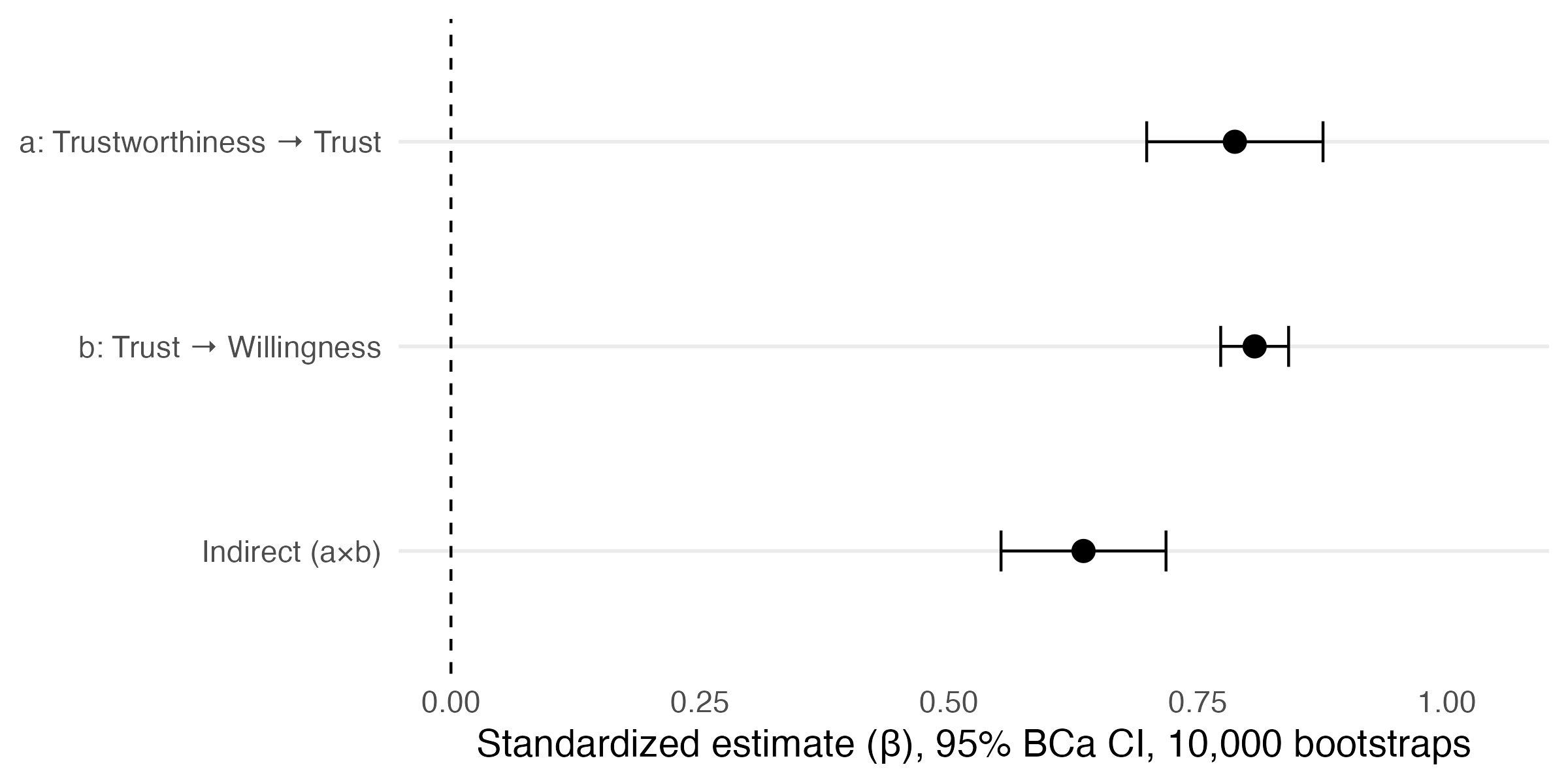
Bottom line: The "human" label won decisively. Citations helped, but not as much as expected. And trust was the key mechanism that turned perception into willingness to act.
Fazit: Das „menschliche" Label gewann eindeutig. Zitate halfen, aber nicht so stark wie erwartet. Und Vertrauen war der Schlüsselmechanismus, der Wahrnehmung in Handlungsbereitschaft umwandelte.
Design: 2×2 between-subjects experiment
Design: 2×2 Between-Subjects-Experiment
Factor 1: Agent Identity (AI vs Human)
Factor 2: Citation Presence (Yes vs No)
Faktor 1: Agentenidentität (KI vs Mensch)
Faktor 2: Quellenangaben (Ja vs Nein)
Data Cleaning Pipeline:Datenbereinigungspipeline:
Measures:Messinstrumente:
Perceived Credibility (Ohanian, 1990) — 6 items, α = .86/.90
Trust in Automation (Jian et al., 2000) — 3 items, α = .93
Willingness to Follow Advice (Komiak & Benbasat, 2006) — 3 items, α = .79
Wahrgenommene Glaubwürdigkeit (Ohanian, 1990) — 6 Items, α = ,86/,90
Vertrauen in Automatisierung (Jian et al., 2000) — 3 Items, α = ,93
Bereitschaft, Ratschlägen zu folgen (Komiak & Benbasat, 2006) — 3 Items, α = ,79
Analysis:Analyse:
Robust 2×2 ANOVA (20% trimmed means, WRS2 package)
Sequential mediation with 10,000 BCa bootstraps (lavaan)
Multi-group SEM for moderated mediation
Robuste 2×2-ANOVA (20% getrimmte Mittelwerte, WRS2-Paket)
Sequentielle Mediation mit 10.000 BCa-Bootstraps (lavaan)
Multi-Gruppen-SEM für moderierte Mediation
Hypothesis Testing Summary:Zusammenfassung der Hypothesentests:
Key Numbers:Wichtige Zahlen:
Human expertise: 6.21 vs AI: 5.95 (+4.4%)
Human trustworthiness: 5.98 vs AI: 5.81 (+2.9%)
Indirect effect (Cred→Trust→Will): β = .64, 95% CI [.54, .76]
Direct effect (Cred→Will): β = .10, ns — full mediation
Menschliche Expertise: 6,21 vs KI: 5,95 (+4,4%)
Menschliche Vertrauenswürdigkeit: 5,98 vs KI: 5,81 (+2,9%)
Indirekter Effekt (Glaub→Vertr→Ber): β = ,64, 95% KI [,54, ,76]
Direkter Effekt (Glaub→Ber): β = ,10, ns — vollständige Mediation
Research & AnalysisForschung & Analyse
Data CollectionDatenerhebung
Stimulus DevelopmentStimulus-Entwicklung
AI AssistanceKI-Unterstützung